Redis数据结构
基础数据结构
SDS
Simple Dynamic String,简单动态字符串,由于C语言内置的字符串底层是字符数组,有诸多不爽的点:二进制不安全(读取时以\0结尾,若字符串本身带有\0字符,则读到这个字符就结束了)、不能动态扩容(就像Java的String一样,不可变)、获取字符串长度需要遍历到结束字符。
所以Redis的作者做了些许改进,自定义了SDS结构,Header存储字符串长度,申请的内存大小,SDS头的类型(8/16/32分别表示 len 和 alloc 所占的字节数,相当于你len <= 255的话,就只需要8位即1字节就可以存储len了)。Body也是一个字符数组,存储字符串本体。

SDS既然叫做动态,那肯定也支持对字符串进行修改,规则如下:
- 如果新字符串小于1M,则申请的新空间为新字符串长度的两倍+1
- 如果大于1M,则新空间为新字符串长度+1M+1(字节)
相当于是内存的预分配策略,避免了频繁申请内存从用户态到内核态消耗CPU资源。SDS优势:
- 维护字符串长度,O(1)时间就能拿到长度
- 不会出现二进制不安全了,虽然结尾也是\0,但是有字符长度的信息,可以直接读取对应的字符串
- 动态扩展、内存预分配减少了申请内存的次数
IntSet

encoding和length在结构体中都是占4个字节的。encoding包含三种模式,表示存储的整数的大小:
1 | |
为什么数组中保存的每个整数的大小必须固定?因为便于寻址,数组其实就相当于是一个指向数据在内存中的起始地址的一个地址,数组是连续存放的,然后根据数据距离起点的距离 * 每个数据的大小(sizeof(encoding))就可以得到某个数据的地址了。
升级:要是当前编码是int16,数据范围是(-2的15次方 = -32768)——(2的15次方 - 1 = 32767)。但是如果此时存入一个大于这个的数比如50000怎么办?IntSet是支持升级的:
- 自动选择合适的encoding
- 倒序移动原有的数据到新的内存地址
- 插入新数据,修改length
Dict
字典,Hash结构,只是比普通的Hash结构外面多包了一层Dict。
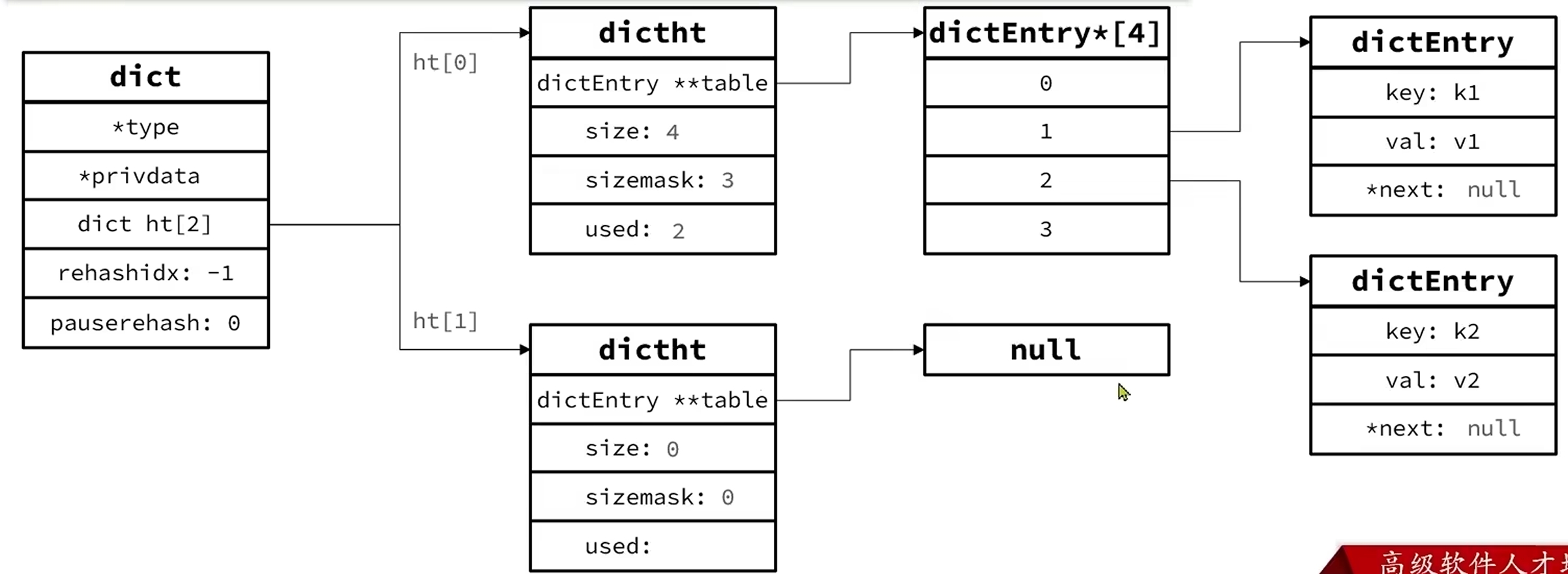
Dict ——> DictHashTable(dht[0]、dht[1]) ——> DictEntry (*key, *value)
其中这个key和value都是指针,指向SDS或其他的数据对象。


往里头插入数据时,先计算出key的hash值k,然后用k&sizemask就可以得到应该插入到哪个桶里去,这里与运算相当于对size取模,一模一样。解决冲突的话同样是链表,头插法。一个大概的Dict结构如下图,其中rehashidx比较关键,代表当前rehash操作执行到哪个位置了,只有为-1时才表示不用进行rehash。
渐进式ReHash
触发条件:
- loadfactor = used / size >= 1:如果没有bgsave或者bgrewriteaof这种命令在后台执行的话,可以rehash
- loadfactor > 5:强制rehash扩容
- 收缩:loadfactor < 0.1 :rehash收缩
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新哈希表,这个过程称为rehash。过程是这样的
计算新hash表ht[1]的realSize,如果是扩容则新size是第一个大于等于ht[0]used + 1的2^n,如果是收缩则size为第一个大于等于ht[0]used + 1的2^n
按照新的realSize申请内存空间,创建 dictEntry table,并赋值给ht[1],同时设置dict.rehashidx=0,标示开始rehash
将dict.ht[0]中的每一个都rehash到dict.ht[1]
为什么叫渐进式rehash?是因为当我们redis中数据量巨大的时候你不可能像上面一样一次性把每一个dictEntry都rehash到dict.ht[1]的dictEntry数组。而是渐进式的,见下文
ht[0] 的 dictEntry table指向这个新的dictEntry table,释放ht[1]的空间
渐进式:每次增删改操作时,都会检查rehashidx > -1,如果是则将dict.ht[0].table[rehashidx ]的Entry链表rehash到dict.ht[1],同时rehashidx ++。而不是一次性迁移。新增操作永远插入ht[1],保证ht[0]的数据只减不增
ZipList
ZipList 是一种特殊的“双端链表”,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,并且
该操作的时间复杂度为 O(1)。
何为压缩?由于Dict全是由各种指针来指向下一个元素,所以内存是不连续的,会浪费内存空间。压缩链表压缩的意义就在于压缩内存空间,首先它的内存是连续的,其次它存储每个entry的节点大小是不固定的,也就是说元素多大就申请多大的内存,极致的内存利用率。
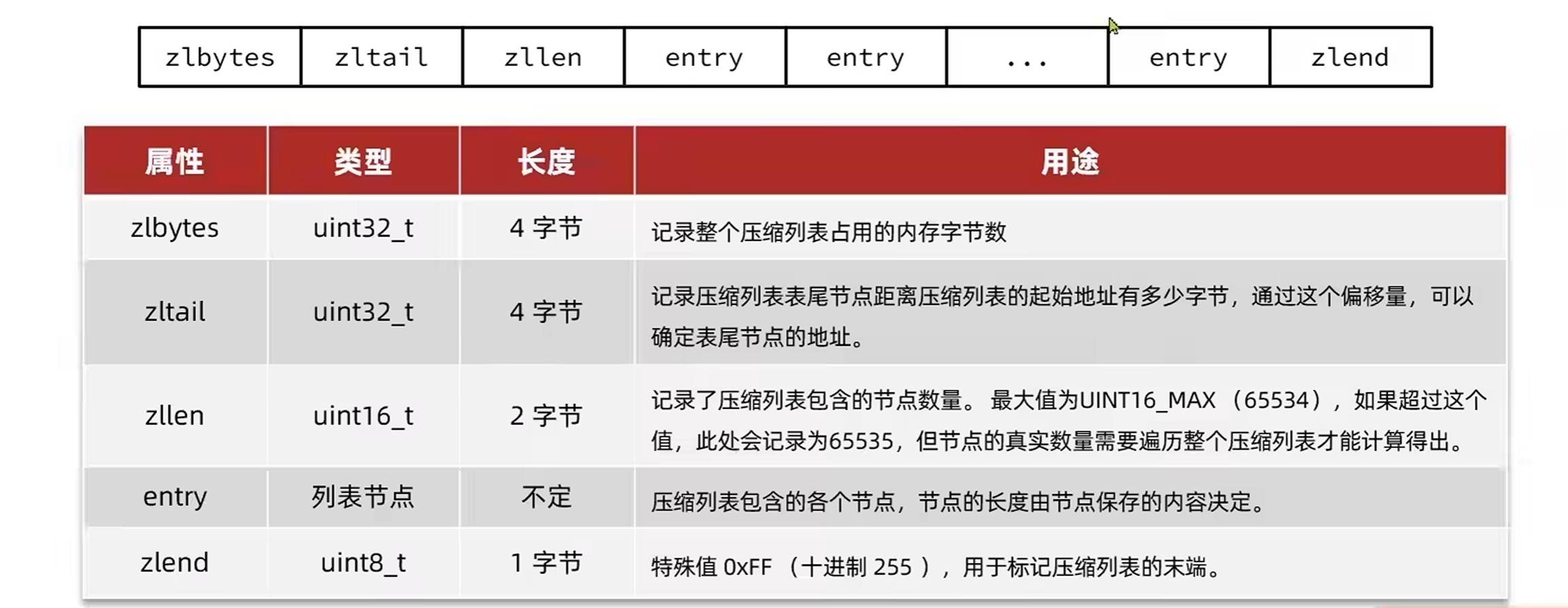
zlbytes、zltail、zllen在ziplist中都是以小端模式存储的,也就是你常规的二进制顺序反过来,见下面的例子
entry就是存储元素的节点,其中每个entry的格式如下:
1 | |
previous_entry_length:上一个节点的长度,占1字节或5字节
如果前一节点长度小于254字节,就用一字节保存这个长度值
否则就用5字节来保存,其中第一字节默认为0xfe,后四个字节保存真实长度
encoding:记录content的数据类型以及content的长度,见下文
content:真实数据,字符串或者整数
encoding:分为字符串和整数两种
- 字符串:00、01、10分别表示不同长度的字符串

- 整数:整数只需要一个11就可以表示了

连锁更新问题
前面说了,如果前一节点长度小于254字节,previous_entry_length就用一字节保存这个长度值,否则用5字节。
假如现在图中这些节点都是250个字节,那他们的下一个节点的previous_entry_length就是1字节

如果此时在最前面插入一个长度为254个字节的节点,那么它后面一个节点的previous_entry_length就需要改为用5字节来存储,同时意味着后面这个节点的长度从250增加到了254个字节,进而导致了再往后的节点也需要更新previous_entry_length值,形成了一个连锁更新的问题。

Redis目前没有解决这个问题,Redis 的设计理念在一定程度上能接受这种连锁更新的情况。因为在实际应用中,ziplist 中的节点数量通常不会非常巨大,而且连锁更新虽然会带来一定的性能开销,但发生的概率相对较低。
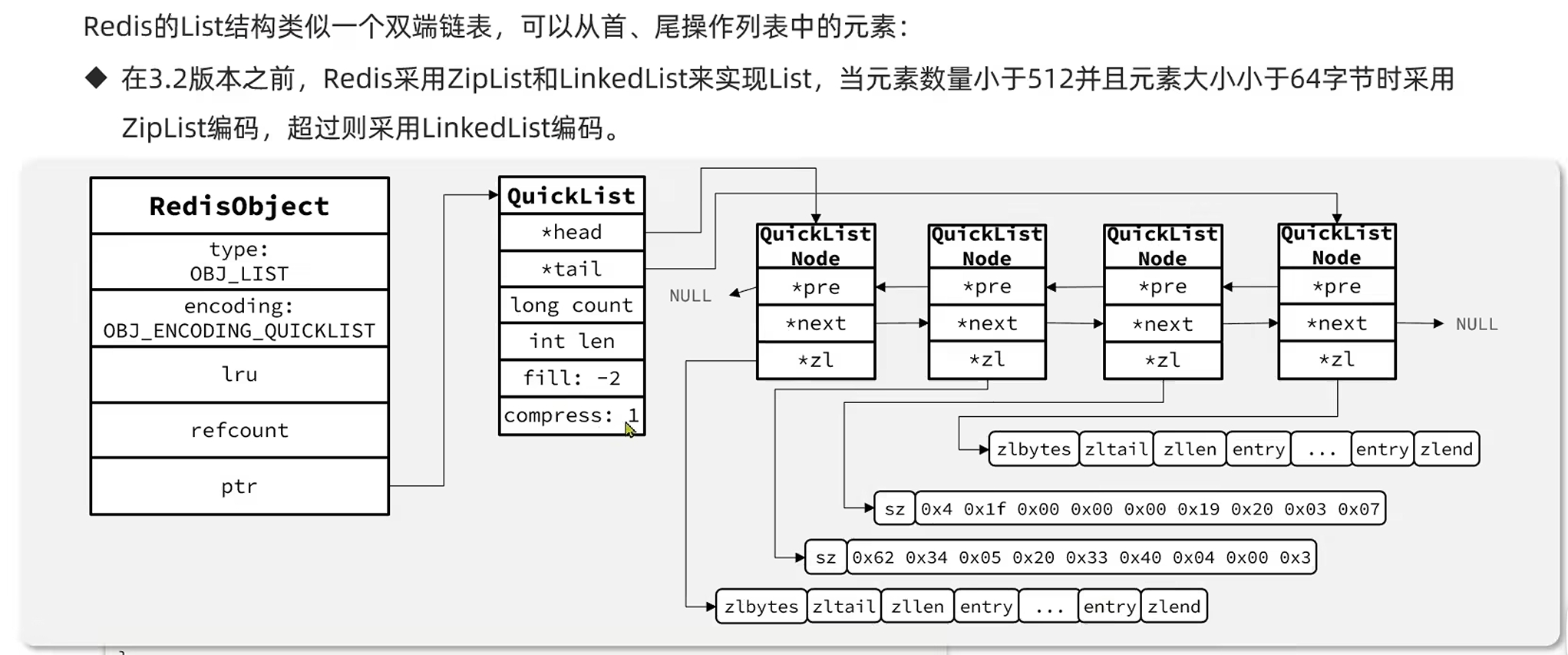
QuickList
Ziplist是基于连续的内存空间,连续空间自然节省内存,不会出现内存碎片,但是申请连续的内存空间也是很麻烦的,特别是数据量大的时候,所以ZipList只适合数据量比较小的情况,数据量大时我们必须限制ZipList的长度和entry大小。
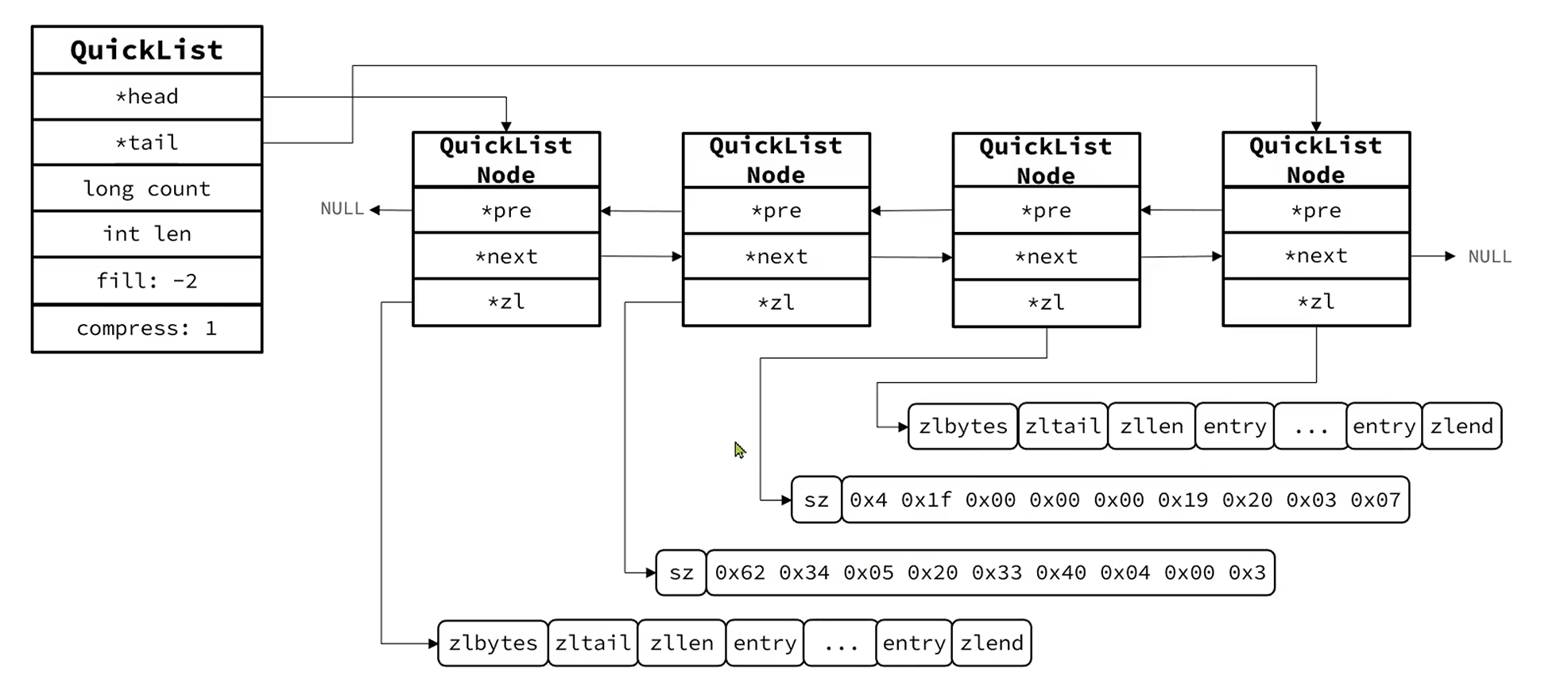
那如果数据量很大怎么办?其实可以采用多个ZipList分片存储,但是数据拆分后不便于查找了,怎么把这些分片联系起来?Redis给出了解决办法,Redis3.2引入了QuickList,她是一个双端链表,每一个表节点都是一个ZipList。
list-max-ziplist-size: 该配置可以限制QuickList中每一个ZipList节点的最大entry数或者ZipList占的最大内存大小,值为正数表示最大entry数量,值为负数,不同的负值表示不同的内存大小,[-1, -5] 对应 [4kb, 64kb]
list-compress-depth: 该配置可以控制QuickList对其首位的ZipList节点不压缩个数,0代表不压缩所有节点,1代表首尾各一个节点不压缩,中间的全部压缩,2,3,4类推
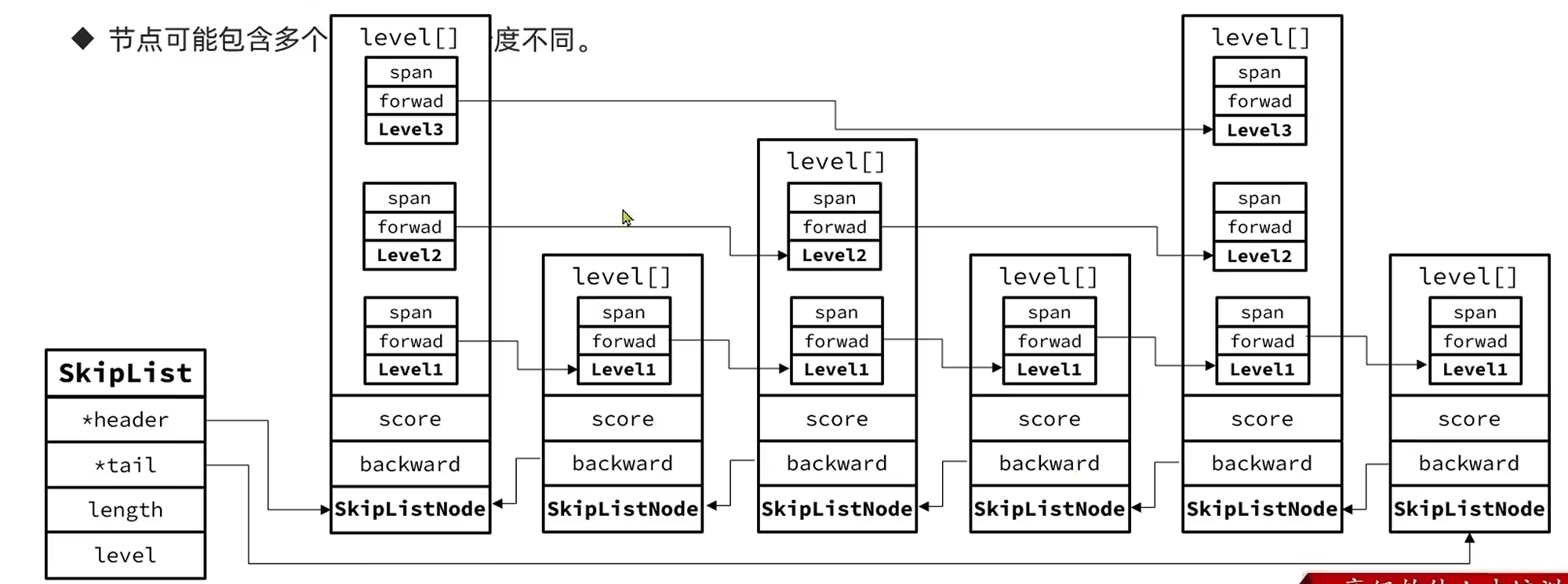
SkipList
QuickList和ZipList从首尾节点开始访问查询性能还不错,但是你要从中间随机查询节点就要一路遍历过去了,性能略拉胯。
Redis又引入了跳表,首先也是链表,只是他的链表节点可能包含多个指针,跳跃着指向更后面的元素
- 元素按照升序排列存储
- 节点包含一个或多个指针,指针跨度不同

可以发现节点存储值是用SDS,多级指针是放在一个level数组中的。大致结构如下图
RedisOBJ
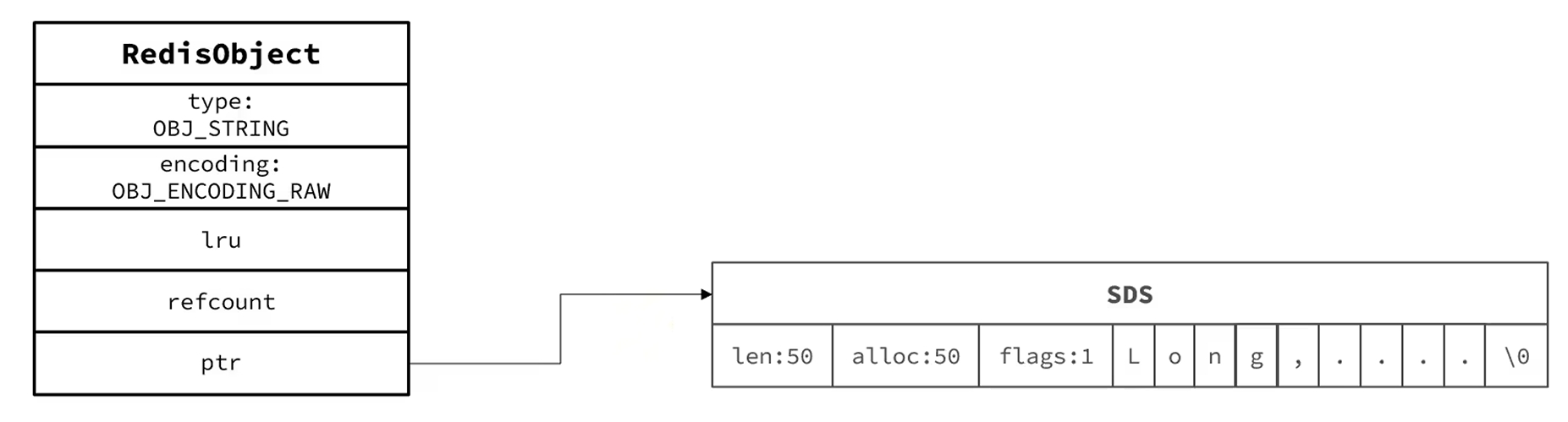
Redis中任意数据类型的键和值都会被封装成RedisObject对象,占16字节。长下面这样:

encoding对应编码格式,编码其实就是指示当前数据是以什么数据结构存储的,以下是不同的数据类型对应的编码和数据结构:
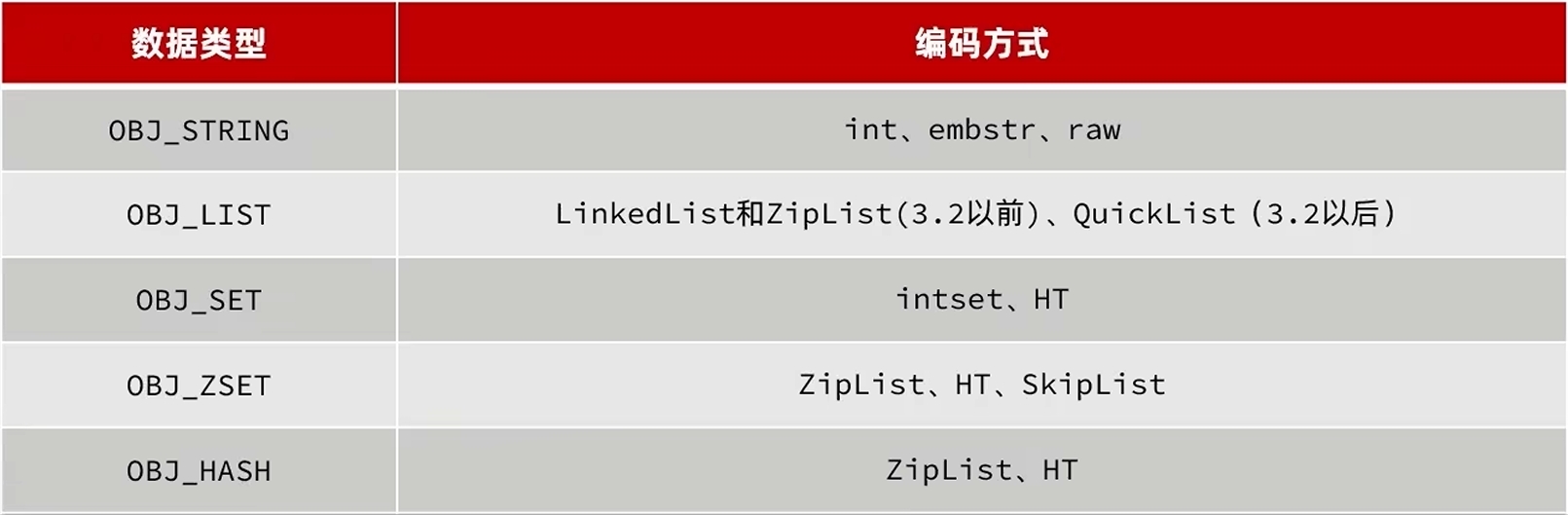
五种数据类型
String
RAW编码
RAW编码下,RedisObject对象的ptr指针指向的是SDS对象,存储上限是512MB。可以发现RedisObject对象和SDS对象的内存是不连续的。相当于有存储这个String的时候有两次内存的申请操作,为RedisObject申请一次,为SDS申请一次,释放也有两次。
注意 big key 问题,可以用–bigkeys指令查看大key
EMBSTR编码
如果SDS中数据的大小小于等于44字节,Redis存储String就会采用EMBSTR编码,唯一区别就是RedisObject和SDS连续了,最大64字节(因为SDS = 44 + len(1字节) + alloc(1) + flags(1) + \0(1) = 48;再加上RedisObject的16字节最大就是64),刚好是一个连续内存页的大小,便于申请,不会有内存碎片
INT编码
如果String是整数并且这个整数在LONG_MAX以内,采用INT编码,根本不需要SDS,因为指针就是8字节,直接把整数保存成ptr就行,相当于支持2的64次方减1的整数范围。
List
说白了,就是在上文QuickList的基础上,包了一层RedisObject的头,具体见下图
Set
元素唯一,不排序
Redis的Set感觉像是模仿了java的HashSet,底层用HashMap的key来存元素,key唯一,value为一个统一的obj,Redis的Set底层就是HT编码(DICT),还是用key来存元素,只是value统一设为null了
同时还支持IntSet编码,当存储的所有数据都是整数,并且数量不超过set-max-intset-entries时,就用IntSet,节约内存,顺序存储,查询和插入都可以二分查找,快。
需要注意的是每次插入元素Redis都会判断编码类型和你插入元素的类型,以做出不同的操作:
- 编码是ht,直接插入
- 编码是IntSet,插入的元素是整数,直接插入
- 编码是IntSet,插入的元素是字符串,IntSet转化为dict
ZSet
ZSet既要支持member按照score排序,又要支持根据member查询对应score,还要支持member必须唯一,单用一个skiplist只能满足排序,害得来个dict才行。
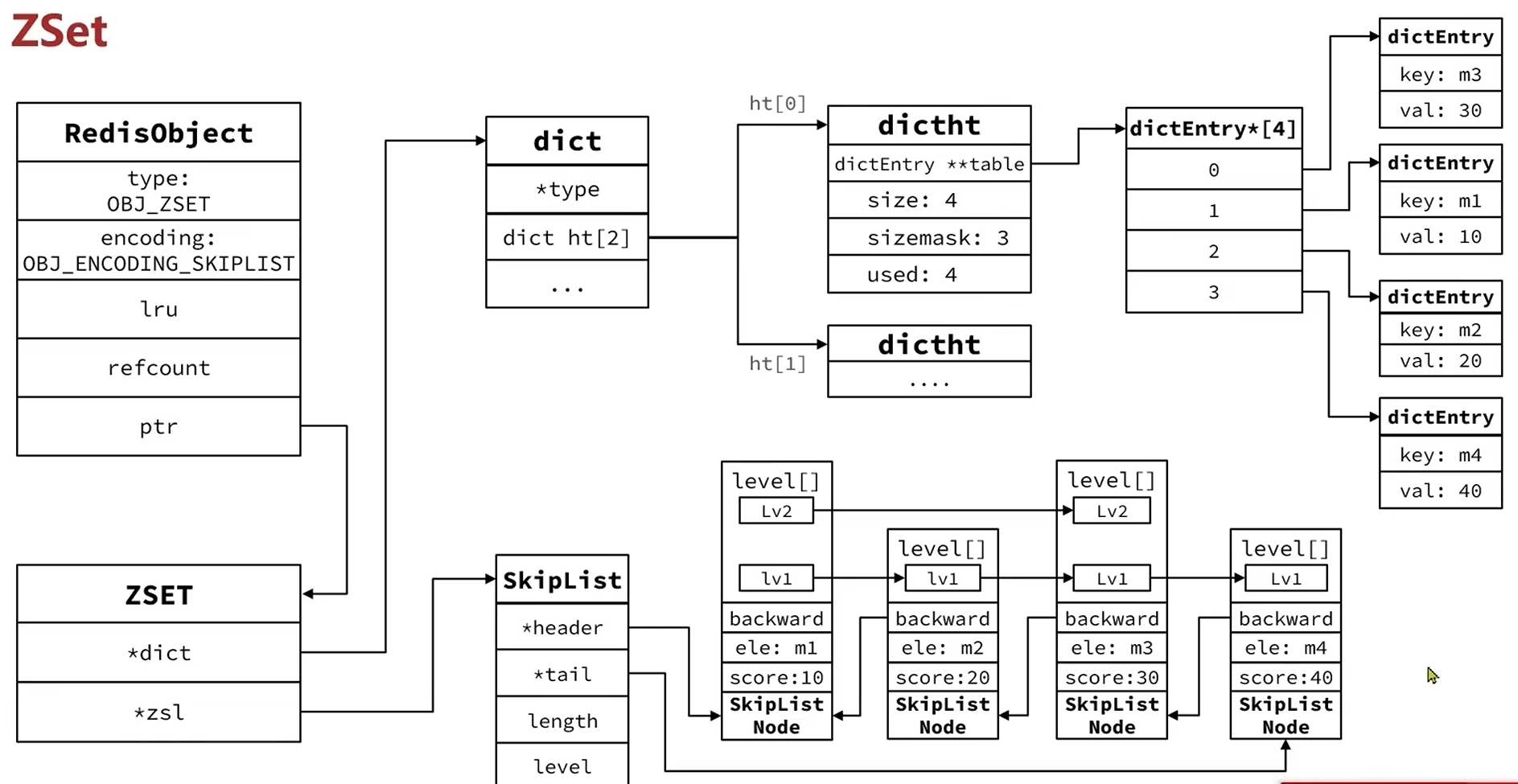
不过,skiplist+dict性能固然优秀,但是非常占内存空间,如果元素满足以下两个条件,可以采用ZipList存储:
- 元素数量小于zset-max-ziplist-entries,默认为128
- 每个元素都小于zset-max-ziplist-value,默认为64字节
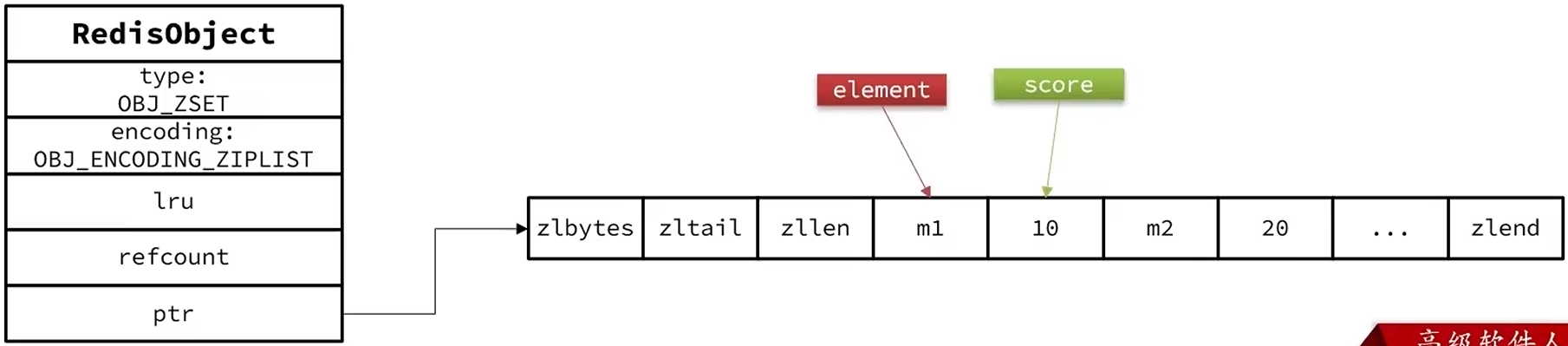
虽然ziplist没有提供键值对,排序等等功能,但是Redis可以先排好序再往里存,同时member一个节点,后面跟着score一个节点也就模拟了键值对了,因为元素个数小于128,所以遍历一遍也不会太慢。
同样需要注意的是每次插入元素Redis都会判断编码类型和你插入元素之后个数会不会超限,以做出转化操作
Hash
类似Zset,但Hash不需要排序了,所以编码只用ziplist + dict(ht)就行。默认先用ziplist:
- 元素数量小于hash-max-ziplist-entries,默认为512
- 每个元素都小于hash-max-ziplist-value,默认为64字节
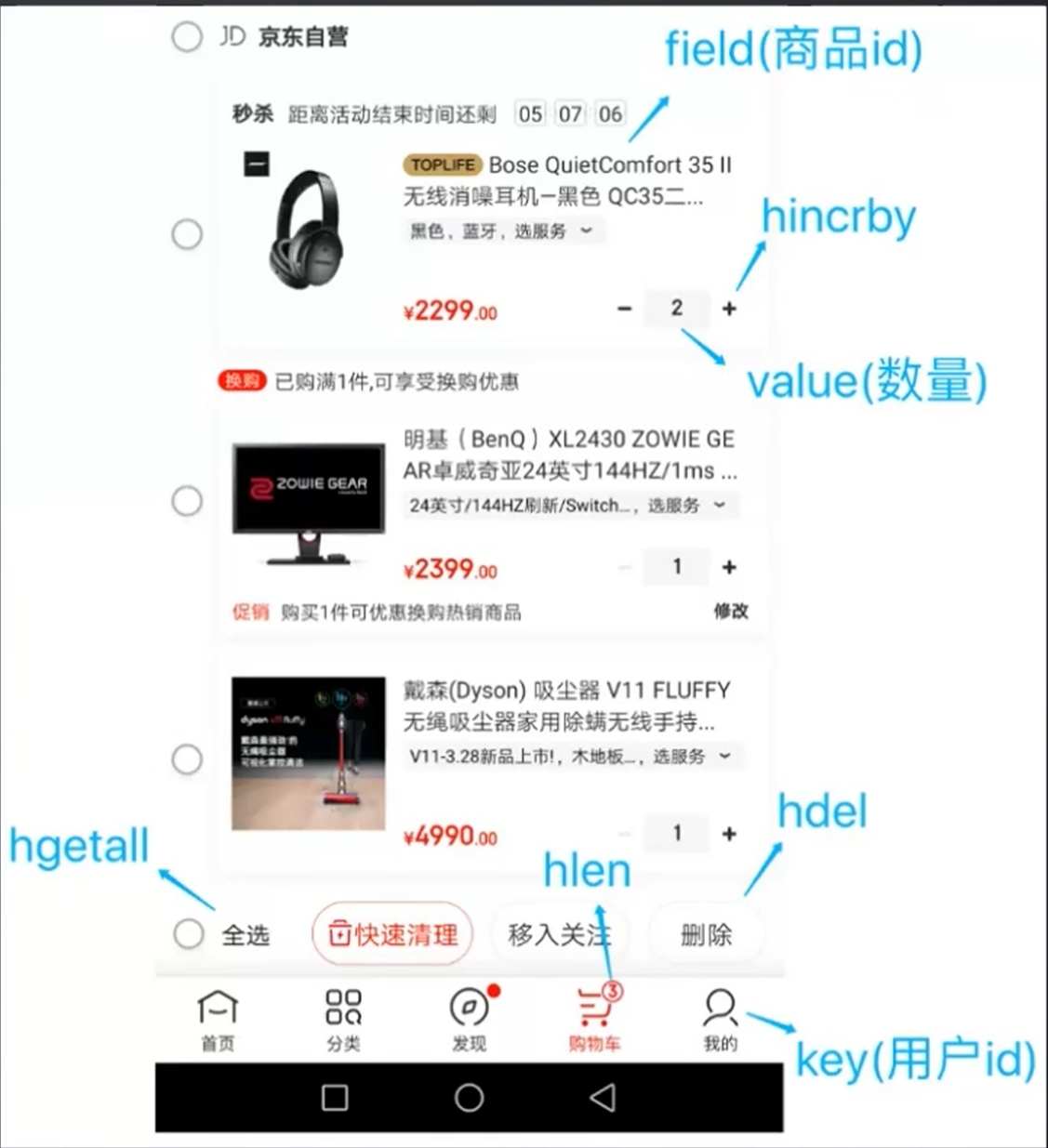
超过这个值就会转化为dict。没什么好说的了。下面这张图我很喜欢: