HTTP总结
HTTP基本概念
一个完整的HTTP请求长什么样子?
1 | |
POST请求示例
1 | |
响应长什么样
1 | |
一条URL(Uniform Resource Locator)
1 | |
- http:协议
- localhost:8080:主机名(ip)和端口号
- /users:资源路径(URI,Uniform Resource Identifier)
- ?:标志查询参数的开始。
- &:多个查询参数之间用
&符号分隔。
HTTP是什么?
HTTP 是超文本传输协议,也就是HyperText Transfer Protocol。
- 超文本:它就是超越了普通文本的文本,它是文字、图片、视频等的混合体,最关键有超链接,能从一个超文本跳转到另外一个超文本。
- 传输:HTTP 是一个在计算机世界里专门用来在两点之间传输数据的约定和规范。
- 协议:它使用计算机能够理解的语言确立了一种计算机之间交流通信的规范(两个以上的参与者),以及相关的各种控制和错误处理方式(行为约定和规范)。
HTTP状态码
- 200 OK:成功
- 3xx:表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 4xx:表示客户端发送的报文有误,服务器无法处理,属于客户端的错误码。
- 5xx:表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
HTTP字段
- Host:客户端发送请求时,用来指定服务器的域名。
1
Host: www.A.com - Content-Length 字段:服务器返回数据的长度。
- Connection 字段:客户端要求服务器使用「HTTP 长连接」机制,
Connection: Keep-Alive - Content-Encoding 字段:服务器返回的数据使用了什么压缩格式。
HTTP无状态
HTTP 无状态(Stateless)是指每个 HTTP 请求都是独立的,服务器在处理完一个请求后不会保留任何与该请求相关的状态信息。这意味着服务器不会自动记住客户端之间的交互,每个请求都被认为是全新的、独立的请求
session
保存在服务端,服务端返回给客户端一个SessionId,以后的每次请求都带上这个Id(客户端通过 Cookie 或 URL 参数将 Session ID 发送给服务器。服务器根据这个 ID 查找并恢复用户的会话状态。),服务端根据Id拿到对应的session恢复用户状态。
基于session的验证码登录
- 客户端请求服务端,传给服务端手机号
- 服务端校验手机号是否合法,生成验证码,保存验证码到session,通过云服务发送验证码给对应手机号,(同时后台生成了cookie并将sessionId附在cookie中返回给了客户端)
- 客户端输入验证码登录,传给服务端手机号和验证码(sessionId也跟随cookie一并传过来了),服务端校验手机号,对比客户端验证码和对应session中的验证码,执行业务逻辑(根据手机号查询用户,没有就创建,有就把部分用户信息保存到session),同时返回这部分用户信息给前端
cookie
用户首次访问服务端后由服务端生成,返回并保存在客户端,通常用来保存用户偏好、跟踪用户行为、保持登录状态。生命周期有仅限浏览器运行时的,也有持久化存储到硬盘的。每次客户端向服务器发起请求时,浏览器会自动将与该域名相关的所有 Cookie 一同发送给服务器。
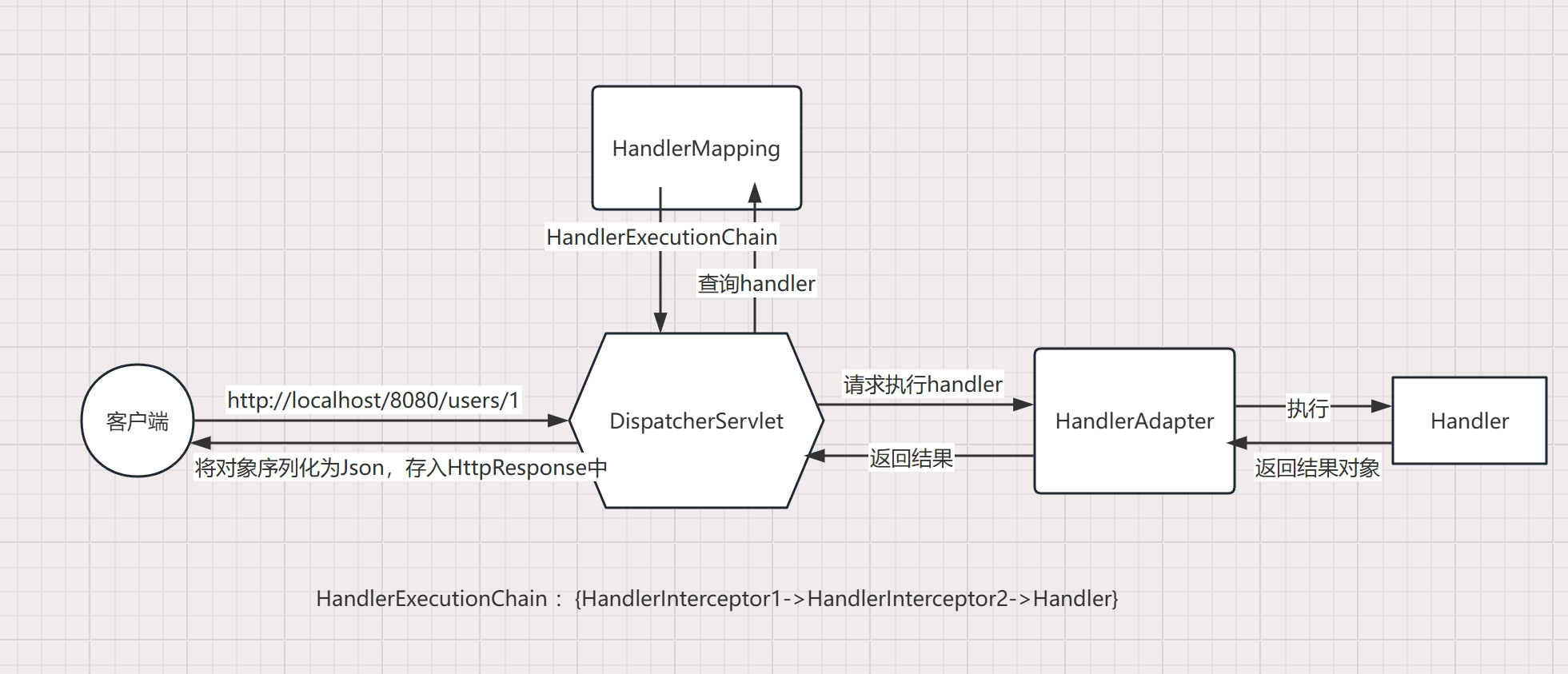
DispatcherServlet
前端控制器,具体见下图
GET/POST
1、GET 和 POST 方法都是安全和幂等的吗?
- 在 HTTP 协议里,所谓的「安全」是指请求方法不会「破坏」服务器上的资源。
- 所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
RFC 规范定义下:
GET 方法是安全且幂等的,因为它是「只读」操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。所以,可以对 GET 请求的数据做缓存,这个缓存可以做到浏览器本身上(彻底避免浏览器发请求),也可以做到代理上(如nginx),而且在浏览器中 GET 请求可以保存为书签。
POST 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。所以,浏览器一般不会缓存 POST 请求,也不能把 POST 请求保存为书签。
HTTP缓存
把重复性的 HTTP「请求-响应」的数据缓存在本地
1、强制缓存
- 只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边。通过HTTP 响应头部(Response Header)的字段
Cache-Control和Expires控制
2、协商缓存
- 通过服务端告知客户端是否可以使用缓存的方式被称为协商缓存。与服务端协商之后,通过协商结果来判断是否使用本地缓存。
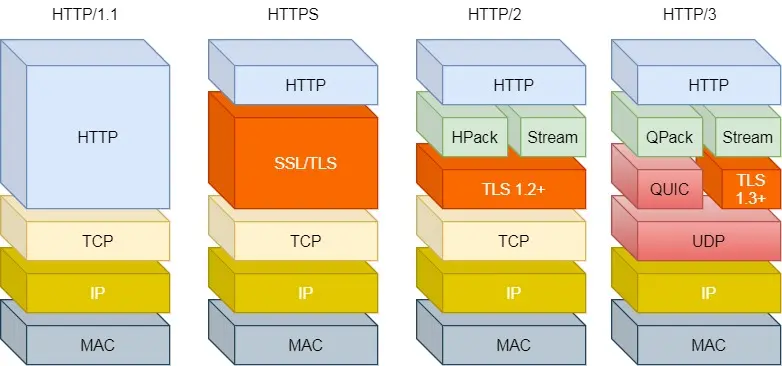
HTTP特性
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
优化:
- 使用长连接(keep-alive)的方式改善了 HTTP/1.0 短连接造成的性能开销。TCP 连接在初次建立后,可以被多次复用。客户端和服务器在一个 TCP 连接上可以发送多个 HTTP 请求和响应,而不需要为每个请求建立新的 TCP 连接。
心跳机制
Keep-Alive: timeout=30, max=100(30秒超时,最多 100 次请求)。
- 支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
缺点:
- 请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩 Body 的部分;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
- 请求只能从客户端开始,服务器只能被动响应;
- 没有请求优先级控制。
HTTP/2 相比 HTTP/1.1 性能上的改进
- 头部压缩
- 二进制格式
- 并发传输(多路复用):意味着客户端可以在一个连接上并行地发送多个请求,而不需要等待其他请求的响应。
- 服务器主动推送资源
缺点:
- 一旦发生丢包,就会阻塞住所有的 HTTP 请求,这属于 TCP 层队头阻塞。
1
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
HTTP/3 做了哪些优化?
HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP!