如何使用数组模拟邻接表
数组模拟邻接表的难点
看了一圈博客、ACwing的解释仍然云里雾里,大多数同学都在绞尽脑汁想给大家讲明白每个数组代表什么含义,什么 e[] 数组啊,ne[] 数组等等。其实差的只是最后一步,就是模拟完add(a, b)建表之后,再带着大家走一遍顺着邻接表读取的过程,瞬间就会豁然开朗,此篇文章适合已经了解了数组模拟邻接表的基本代码和原理但仍然云里雾里的同学。
一、建表
补充一点初始条件:idx初值为0,h[]数组中的每个值已被初始化为-1,即:h[-1, -1, -1, -1, -1]。你先不管为什么初始化为-1,看到后面就明白了。
先贴代码
1
2
3
4
5void add(a, b) {
e[idx] = b;
ne[idx] = h[a];
h[a] = idx ++;
}如下图,请按照add(1, 2)、add(2, 4)、add(1, 3)、add(3, 4)的顺序构建邻接表,现在你不用管那些数组是什么意思,只需要按照add方法往几个数组中更新值就行
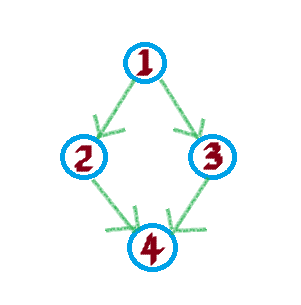
最后得到和我一样的几个数组就算胜利:
| 数组下标 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| h | -1 | 2 | 1 | 3 | -1 |
| e | 2 | 4 | 3 | 4 | |
| ne | -1 | -1 | 0 | -1 |
此时idx的值为3
再次补充前置知识:初始情况下,邻接表为中元素1后面没有连接任何元素,可以理解为 1 -> -1,这里-1代表后面没有元素。add(1, 2) 后,即在1后面插入2,就变成 1 -> 2 -> -1,add(1, 3)后,变成1 -> 3 -> 2 -> -1,可以发现add操作是在表头后面插入新元素的,而不是在链表的尾部插入。
二、开始模拟
- 只需一遍,你就会明白
- 如果我们想获取结点1对应的这个链表,即获取 1 -> 3 -> 2,首先找到 h[1] = 2,那么 e[2] = 3 就是结点1的在表中的下一个结点,即 1 -> 3;接着ne[2] = 0就代表再下一个结点在e[0]处,e[0] = 2, 即1 -> 3 -> 2;接着ne[0] = -1就代表没有下一个结点了,即1 -> 3 -> 2 -> -1,怎么样是不是很简单。
- 所以可以总结出:e数组就是存放下一个结点的数组,而ne数组是存放去e数组的哪个位置找结点的数组
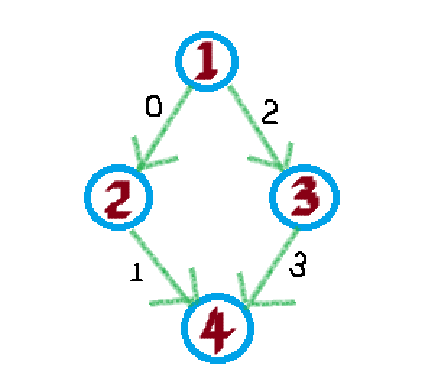
- 再看这张图,可以发现,我们调用add()函数建表时就是用idx来给每条边编号的,同时h数组中存放的就是每个结点到它的下一个第一个结点的边的编号,例如 2 -> 4,查询h[2] = 1,即为图中对应边的编号。
如何使用数组模拟邻接表
https://payfish.github.io/2024/04/03/数组模拟邻接表/